
摘要:2023年1月份,我们发布了SPARK数据库更新,本次发布新增源于专利文献报道的化合物片段库SureChEMBL,大大扩展了Spark用户可获取的化学知识,结合来自筛选化合物的片段数据库以及自定义数据库,Spark数据库提供了卓越的生物等排体来源,可以用来为你的项目产生新的想法。
Spark更新了ChEMBL片段数据库,并新增SureChEMBL片段数据库。新发布的数据库包含了科技文献中的最新化合物以及化学专利中以前未见过的化合物,大大扩展了Spark用户可获取的化学知识。结合来自筛选化合物的片段数据库,以及用Spark数据库生成器从企业自用数据库生成的自定义数据库,Spark数据库提供了卓越的生物等排体来源,可以用来为你的项目产生新的想法。
160多万片段源于ChEMBL
更新后的Spark ChEMBL数据库包括来自ChEMBL第30版160多万个片段。ChEMBL数据库收录了经同行评议科学文献报道的210多万化合物。
1400多万片段源于SureChEMBL
此外,Spark用户首次可以使用新的SureChEMBL片段数据库,其包含1400多万片段,源自于专利文献报道的约1700万化合物的SureChEMBL数据库。这一添加为Spark用户显著拓展了ChEMBL片段库,提供了比以往更广泛的可访问化学空间。
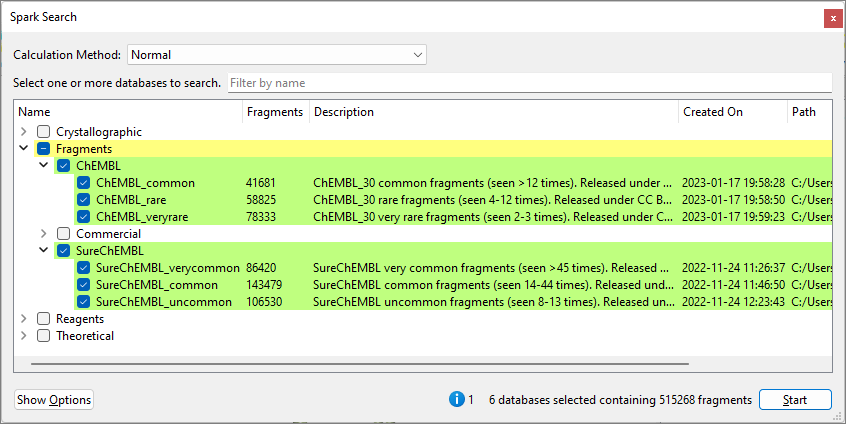
图1. R-基团替换实验的Spark搜索窗口,显示具有单个附着点的默认ChEMBL和SureChEMBL片段数据库
与ChEMBL一样,SureChEMBL化合物具有合成易处理性、毒性和代谢反应性等特性信息。原始来源数据库中的化合物在Spark中碎片化之前根据这些生化特性进行过滤,去除了含有潜在毒性或反应性基团的分子。然后通过断开连接碳原子和官能团(例如杂原子、羰基、硫代羰基和环)的键来裂解化合物,同时保留官能团(例如羧酸、硝基和环)。所有片段都受到重原子计数和可旋转键限制的影响,这增加了片段形成生化活性小分子之一部分的可能性。最后,片段按源数据集中的出现频次排序,并按共性分组以形成Spark数据库。Spark用户的一个关键假设是,经常出现的片段可能是构成新型活性生物化学的一部分,因此我们建议用户在使用不太常见的库之前先尝试更常见的库。
表1报告了每个Spark数据库中的片段总数,以及在源数据集中出现的频次。任意选择数据库频次以管理的数据库文件大小。
表1. 按频次对片段数据库进行分组
| Spark category | Database | Total number of fragments (x1000) | Frequency in source dataset |
|---|---|---|---|
| ChEMBL | Common | 232 | Fragments which appear in more than 12 molecules |
| Rare | 304 | Fragments which appear in 4-12 molecules | |
| Very Rare | 390 | Fragments which appear in 2-3 molecules | |
| Extremely Rare | 783 | Fragments which appear in 1 molecule | |
| SureChEMBL | Very Common | 509 | Fragments which appear at least 45 molecules |
| Common | 795 | Fragments which appear in 14-44 molecules | |
| Uncommon | 554 | Fragments which appear in 8-13 molecules | |
| Rare | 957 | Fragments which appear in 5-7 | |
| Very Rare | 757 | Fragments which appear in 4 molecules | |
| Extremely rare | 979 | Fragments which appear in 4 molecules | |
| Doubleton | 2545 | Fragments which appear in 4 molecules | |
| Singleton | 4794 | Fragments which appear in 1 molecule |
按化合物连接点数量来统计数据库,结果如图2所示。
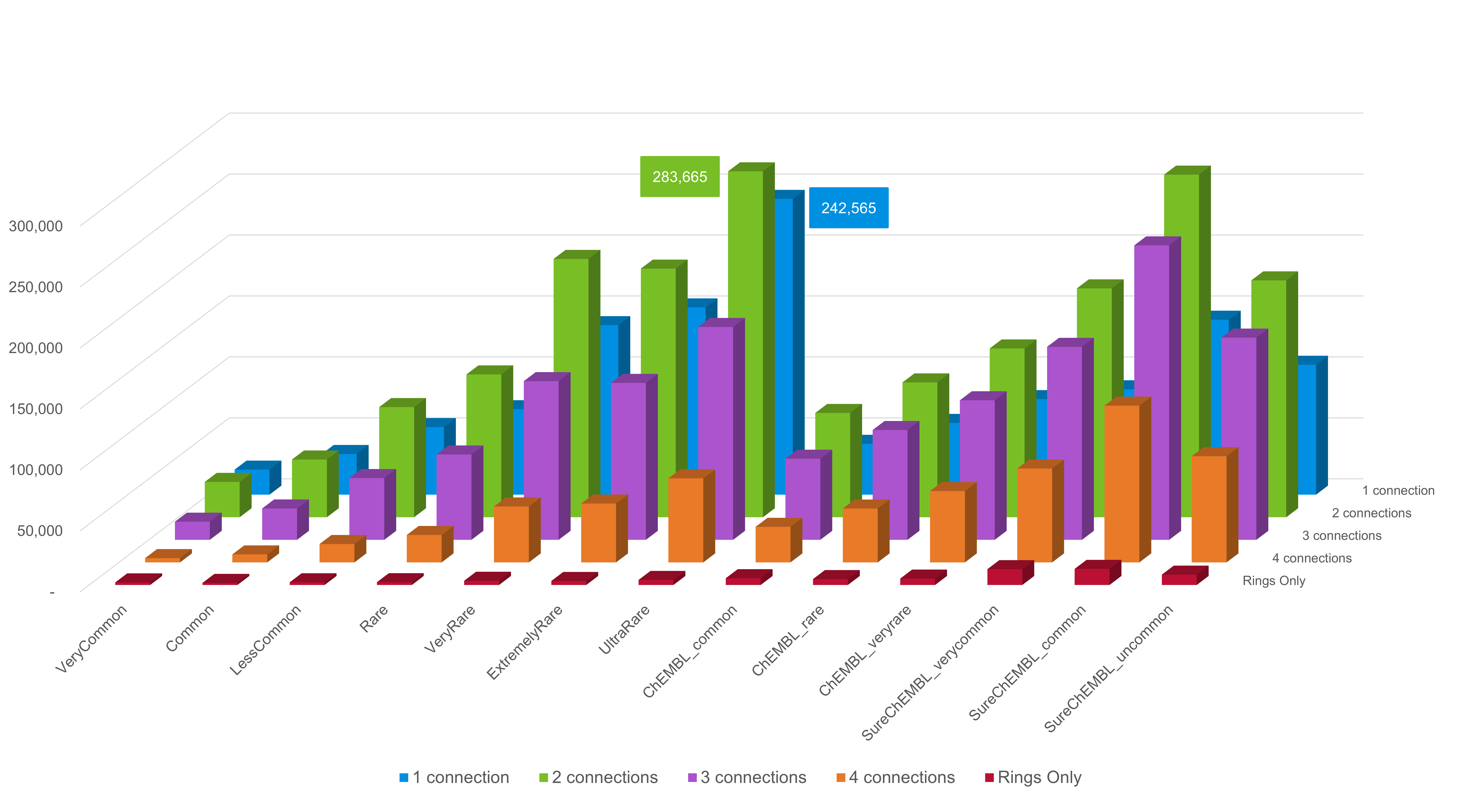
图2. 按每个片段上的连接点数划分,推荐的Spark Commercial、ChEMBL和SureChEMBL数据库中的片段数量统计结果。
我们建议用户只安装片段频率至少为2的ChEMBL数据库,以及三个 SureChEMBL“通用”数据库(Very Common、Common和Uncommon),因为SureChEMBL数据库非常大。此外,ChEMBL和SureChEMBL的Singleton和Doubleton数据库可能包含源自源数据集中错误结构的片段。
尽管ChEMBL和SureChEMBL片段来源不同(科学文献与专利),但正如预期的那样,一些数据库之间存在显着重叠,如表2所示。特别是,ChEMBL Common和SureChEMBL Very Common数据库重合最大,这是意料之中的,因为大多数生物活性化合物都含有基本子单元,例如苯酚或吡啶环。
表2. ChEMBL与SureChEMBL最常见片段的重合
| SureChEMBL | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Very Common | Common | Un-Common | Rare | Very Rare | Extremely Rare | Doubleton | Singleton | Unique | ||
| ChEMBL | Common | 66% | 14% | 3% | 3% | 1% | 1% | 2% | 2% | 8% |
| Rare | 28% | 21% | 7% | 7% | 3% | 3% | 4% | 5% | 23% | |
| Very Rare | 13% | 17% | 7% | 8% | 4% | 5% | 7% | 6% | 33% | |
| Extremely Rare | 6% | 10% | 6% | 7% | 4% | 5% | 8% | 13% | 42% | |
试剂数据库
Spark试剂数据库的1月更新包括使用一组增强的化学转化规则从eMolecules砌块派生的约293,000种试剂。该数据库每月更新一次,为您提供最新的可供购买信息,让您轻松订购合成您最喜欢的Spark结果所需的试剂。
升级您的数据库
更新后的ChEMBL和新增的SureChEMBL数据库,与Spark Commercial 片段数据库相结合,总共提供了1900多万个独特片段可供搜索,仅推荐数据库中就有超过460万个片段。它们显着扩展了您的Spark实验的片段选择,为您的药物发现项目提供了更好的新想法来源。
Spark用户可以联系我们的支持团队来更新他们的ChEMBL和SureChEMBL数据库。
如果您是药物化学家或计算化学家且目前未使用 Spark,请联系我们以了解它如何帮助您产生创新想法、探索化学空间并规避IP和毒性陷阱,或者申请使用以在您的项目中试用Spark。


