
摘要:目前发布的Spark数据库来自有商品可供购买的筛选化合物、文献、商品可供购买的试剂、小分子晶体结构(结晶学开放数据库和剑桥结构数据库)以及理论环系(VEHICLe)等等。本文详细说明了这些片段库与试剂库的组成、来源以及分布特点,并介绍了如何创建自己的片段库与试剂库。
关于SPARK数据库
目前发布的Spark数据库来自有商品可供购买的筛选化合物(eMolecules screening compound1)、文献(ChEMBL2)、商品可供购买的试剂(eMolecules building block3)、小分子晶体结构(结晶学开放数据库4和剑桥结构数据库5)以及理论环系(VEHICLe6)等等。请按照Spark的手册将数据库更新到最新版本,简单来说鼠标点击:File | New project | Update Database。
源于筛选化合物(screening compounds)的片段
商业Spark数据库基于eMolecules的筛选化合物,并根据片段出现的频率进行拆分。
- VeryCommon (477 MB) – 在725个以上分子里出现过的片段
- Common (961 MB) – 在215-724个分子里出现过的片段
- LessCommon (1.95 GB) – 在65-214个分子里出现过的片段
- Rare (2.68 GB) – 在25-64个分子里出现过的片段
- VeryRare (5.3 GB) – 在9-24个分子里出现过的片段
- ExtremelyRare (5.8 GB) – 在5-8个分子里出现过的片段
- UltraRare (8.1 GB) – 在3-4个分子里出现过的片段
总的来说,来自VeryCommon或Common数据库的片段更可能容易合成,因为它们出现在许多不同的商品可供购买的分子中。VeryRare、ExtremelyRare和Ultrare数据库中的片段更可能并不类药或者难以制备。数据库已过滤处理以去除潜在的毒性或反应性片段(如卤代烷或亚硝基官能团)。此外,由于含磷官能团场的计算仍在开发中,因此所有含磷的片段都被去除。有关这些数据库的详细分析,请参见下文。
还有两个非标准配置(可选)的数据库可供选用:
- Doubleton (2 files, each of 5.7 GB) – 在2个分子里出现过的片段
- Singleton (3 files, each of 9.3 GB) – 在1个分子里出现过的片段
通常,我们建议只安装那些在原始数据库中至少出现3-4次片段的数据库。低频片段的数据库非常大,可能包含有原始数据库中不现实/错误结构的片段。如果您需要下载这些数据库,请与技术支持联系。
源于ChEMBL的片段
当前版本的ChEMBL Spark数据库是基于ChEMBL 26,并根据片段出现的频次进行拆分:
- ChEMBL_common (1.9 GB) – 在12个以上的分子里出现过的片段
- ChEMBL_rare (2.5 GB) – 在4-12个分子里出现过的片段
- ChEMBL_veryrare (3.3 GB) – 在2-3个分子里出现过的片段
还有一个非标准配置(可选)的片段库,若需要请联系Cresset技术支持:
- ChEMBL_extremelyrare (5.3 GB) – 在1个分子里出现过的片段
试剂
Spark试剂数据库来源于eMolecules的砌块(building block), 用Cresset的Reagent importer将用到的试剂转化为对应的R基团。比如,以eMolecules_acid数据库为例,所有含有一个C(=O)OH或C(=O)Cl的eMolecules砌块都被处理作为R基团添加到数据库里。
使用有商品可供购买的试剂数据库可以确保Spark实验结果的分子具有良好的合成可行性。该数据库每月更新一次以确保试剂有可靠地供货保障。
当前版本的Spark试剂数据库包含了23个常见的化学转化,详见后面的相关数据库分析。
源于小分子晶体结构的片段
该数据库的片段构象为晶体构象,源于小分子晶体结构。SPARK COD数据库的片段源于Crystallography Open Database,所有的Spark用户均可下载。Spark CSD片段数据库源于剑桥结构数据库(Cambridge Structural Database,CSD),需要有效的CSD-系统授权才能使用该数据库。如果您想用CSD片段数据库,请联系CCDC。
理论环系
理论环系源于VEHICLe6数据库。
创建自己的数据库
Spark片段和试剂数据库为你提供了优秀的生物等排体来源。如果你想将自己专有的化合物、试剂或者库存试剂创建自己的片段库以增加Spark实验价值,那么你可以使用数据库生成器(Spark中用来创建自定义数据库的用户界面)或使用命令行中的等效功能,可以轻松创建自定义数据库。如果您需要Spark数据库生成器方面的帮助,请联系Cresset技术支持。
自定义数据库教程:SPARK教程 | 分子碎片化创建自己的可搜索数据库
自定义数据库教程:SPARK教程 | 如何导入试剂创建自己的可搜索数据库
片段数据库的分析
数据库重合(片段同时在两个数据库出现的数量)
片段与连接点的数量)
分子量的分布
原子数的分布
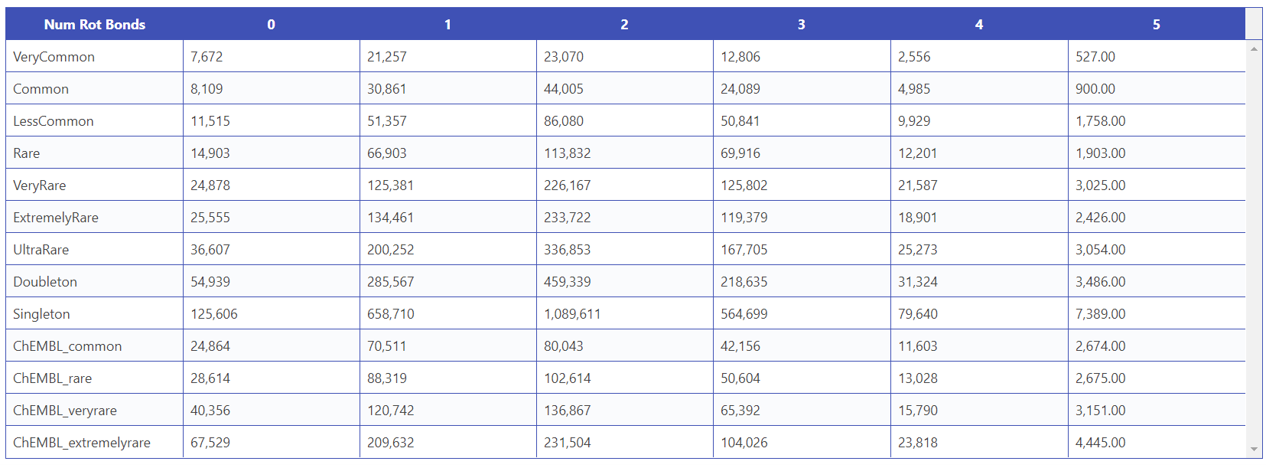
可旋转键数的分布
构象数的分布
试剂数据库的分析
特定分子量范围的片段数
下表的数据是粗略的,试剂数据库精确的片段数随着每月的更新而更新。请确保您的试剂数据库得到更新。
分子量范围分布
文献
- https://www.emolecules.com/info/products-screening-compounds
- https://www.ebi.ac.uk/chembl/
- https://www.emolecules.com/info/products-building-blocks
- http://www.crystallography.net/cod/
- https://www.ccdc.cam.ac.uk/solutions/csd-system/components/csd/
- Pitt, W. R.; Parry, D. M.; Perry, B. G.; Groom, C. R. Heteroaromatic Rings of the Future. J. Med. Chem. 2009, 52 (9), 2952–2963 ftp://ftp.ebi.ac.uk/pub/databases/chembl/VEHICLe


