
摘要:支持向量机 (SVM) 是在药物发现分子性质预测中最常用的机器学习方法之一。近年来,深度学习(DL)方法在药物发现中越来越受欢迎,无论是用于性质预测还是化学空间探索,这引发了SVM是否会被DL取代的问题。然而,正如Bajorath教授最近指出的那样,SVM等传统机器学习模型在药物发现的现代QSAR任务中仍然发挥着不可替代的作用。本文不仅介绍了SVM基本原理,还详细介绍了Flare SVM以及在药物发现中的应用。
作者:Qi Yuan(苑琪)/2022-04-26
编译:肖高铿/2022-05-03
支持向量机 (Support Vector Machine,SVM) 是在药物发现分子性质预测中最常用的机器学习方法之一。近年来,深度学习(deep learning,DL)方法在药物发现中越来越受欢迎,无论是用于性质预测还是化学空间探索,这引发了SVM是否会被DL取代的问题。然而,正如Bajorath教授[1]最近指出的那样,SVM等“传统”机器学习模型在药物发现的现代QSAR任务中仍然发挥着不可替代的作用。
SVM简介
SVM是一种有监督的机器学习算法,可用于化合物分类与数值型的分子性质预测。SVM模型的开发依赖于从训练集中定位支持向量 (support vector,SV)。对于化合物分类任务,SV用于定义具有最大边距的超平面以便将化合物分离(图 1,左)。对于回归任务,SV用于定义具有一定容差(error tolerance)的性质预测的超平面(图 1,右)。
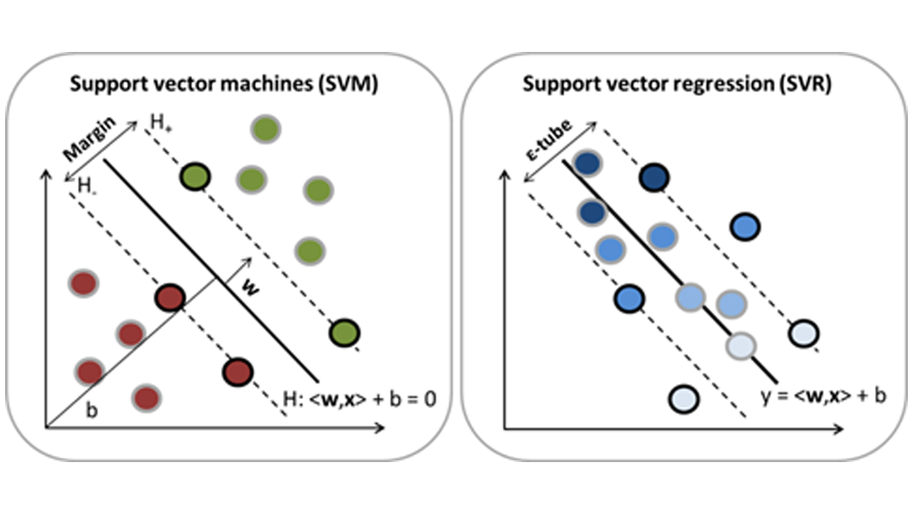
图1. SVM用于分类(左)与回归(右)的示意图,图片来源于文献1。
“核技巧”(kernel trick)在SVM建模中非常重要。化学信息学任务的数据点在给定的输入空间中通常不是线性可分的,并且可以应用核技巧将训练集数据映射到数据可以线性可分的更高维空间。如图2所示,空间 ?中的标量乘积通过非线性映射函数ø投影到更高维度,并且数据在投影空间?中变得可分离。
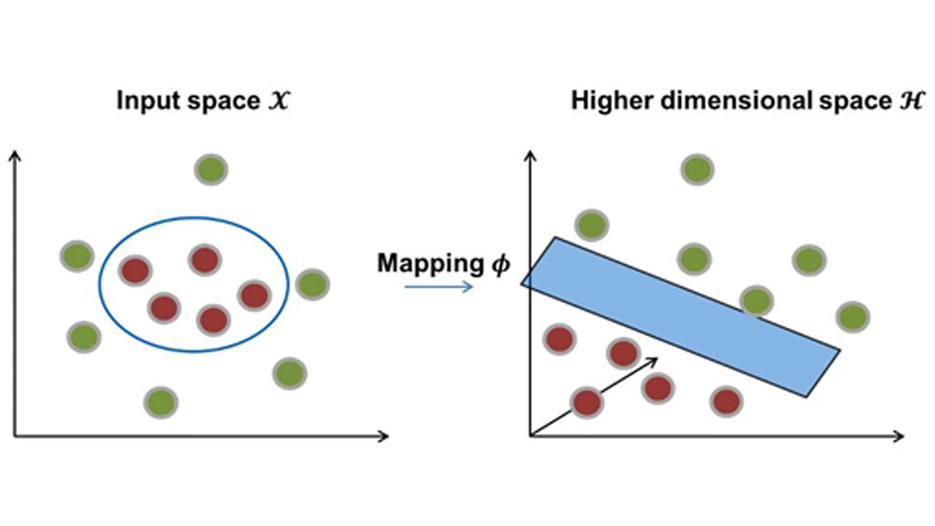
图2. 用核Φ将输入数据投影为更高、更可能线性分离的维度,图片来源于文献1。
对于SVM分类和回归模型,应在模型准确性(做出正确的预测)和泛化性(确保SV之间的较大间隔)之间取得折衷。正则化参数C需要优化。较大的C可以更准确地拟合训练集数据,同时过度拟合的可能性也更高。较小的C导致更简单的决策边界,可以更好地泛化到未见过的数据上。
在药物发现中使用SVM
SVM是化学信息学中一种重要的机器学习方法,因为它在化合物分类和用于虚拟筛选的非线性QSAR方面都具有很高的准确性。SVM还可以适应于特殊应用,例如多靶标活性预测、新靶标识别和活动悬崖预测[1]。
随着近年来深度学习(DL)模型的出现,用于化学信息学任务的DL模型受到了很多关注。但是,在不久的将来,SVM 等“传统”模型不太可能被DL模型取代。当前的DL模型非常适用于有大量非结构化数据可用且表示学习很重要的任务。然而,对于药物发现的许多预测性任务,只有有限的数据可用,并且与用于训练DL模型的非结构化图像或文本数据相比,此类数据通常具有更好的定义。因此,与SVM等更传统的机器学习模型相比,DL模型在药物发现QSAR的预测任务中几乎没有优势。未来,这两种模型可能会很好地结合起来,其中可以使用 SVM 模型执行预测任务,而以数据驱动的方式从DL模型中获得分子表示。
Flare中的SVM
基于scikit-learn[2]中的 SVM 包,在 Flare 中很容易为分类和回归任务生成2D和3D SVM模型。
可以计算静电场和体积场并将其用作化合物的描述符。一系列内核可用于SVM建模,包括sigmoid、RBF、线性、多项式和预计算核。C(正则化)、gamma(RBF核)和epsilon(回归模型中的容差)等参数的调整是在训练集上使用k-fold grid search进行的——可以自动获得具有最佳预测能力的参数组合无需用户干预。
Flare 中提供了一系列模型性能的评估指标。分类模型的性能可以通过混淆矩阵和相关统计数据来衡量,例如精确度、召回率和信息度( informedness)。回归模型的性能可以通过r2/q2、RMSE和Kendall’s tau等统计数据以及通过PCA图检查描述符景观来衡量。训练、交叉验证和测试集的模型性能可用Flare GUI进行可视化(图 3)。与Flare中的大多数其他功能一样,所有方面都可以通过Python API进行控制,从而使自动化变得轻而易举。
总之,对于药物发现中每天遇到的大多数QSAR问题,几乎没有证据表明深度学习方法优于支持向量机等更传统的机器学习工具。Flare中的新QSAR框架比以往任何时候都更容易生成和使用3D-QSAR描述符来构建具有良好预测性和通用性的模型,并且提供了工具与简单指导以实现如何最好地对数据建模、对数据数量与质量问题进行标注、并对新设计的分子进行预测。如果您尚未尝试在Flare中开发QSAR模型,请联系我们取得试用版进行评估!

图3. Flare SVM性能可视化——一个回归任务的演示
文献
- Rodríguez-Pérez, R.; Bajorath, J. Evolution of Support Vector Machine and Regression Modeling in Chemoinformatics and Drug Discovery. J. Comput. Aided. Mol. Des. 2022, 1–8.
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; Vanderplas, J.; Passos, A.; Cournapeau, D.; Brucher, M.; Perrot, M.; Duchesnay, E. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830.


