
摘要:命令行方法使用高性能计算资源阻碍了HPC的可用性,传统的商业软件将计算资源限制于单机方法也限制了用户对高性能计算的利用。本文演示了Ligandscout-remote如何使用云端高性能计算资源加速Ligandscout的虚拟筛选以实现加速药物发现。
Ligandscout-remote:图形界面与高性能计算的无缝集成
HPC集群在科学研究中起着重要的作用。 但是,使用群集通常很麻烦,尤其是对于没有正式计算机科学背景的研究人员而言。它需要准备和传输输入数据,手动收集结果以及命令行使用等专业知识。当前改善远程HPC群集可访问性的方法主要集中在提供基于Web的图形前端,这些前端允许将作业提交到群集上的分布式资源管理系统(scheduler)。与命令行用法相比,这具有显著的可用性优势,但并未绕过手动处理输入和输出文件的需求。尤其对于初学者,任何命令行都是痛苦的挑战。
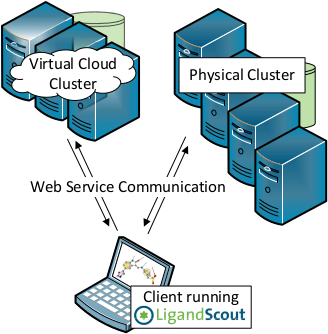
Figure 1. LigandScout可以无缝的调用本地局域网内HPC资源与云端计算资源
LigandScout Remote[1]支持将高性能计算(HPC)资源无缝集成到LigandScout桌面应用程序中,通过对用户透明地处理必要的数据转换和网络通信,避免了HPC的可用性障碍:用户在Ligandscout的图形界面下,即可使用本地高性能计算资源或云端计算资源完成计算任务。
LigandScout除了可以使用本地高性能计算资源之外,其另一优势是支持云计算。这对没有高性能计算资源的用户特别有利:通过按需租用云计算资源进行高性能计算,在不增加预算的情况下可以使用尽可能多的CPU、尽可能快速的获得计算结果。
本教程演示了如何在本机本上通过LigandScout调用云端计算资源完成虚拟筛选。LigandScout-Remote让您无痛、便捷的使用云端HPC计算资源快速地获得计算结果。
操作步骤
1. 云端软件的安装与配置
LigandScout通过局域网内物理HPC或云端虚拟HPC的分布式资源管理系统来实现云计算,LigandScout对云端的要求如下:
- Linux操作系统
- 资源管理系统:SGE, PBS, TORQUE与SLURM
- Java Version 1.8+
在本算例中,云计算资源采用深圳云端科技有限公司(简称:cloudam)的云E算力平台。如何在cloudam上创建管理节点、并设定计算节点的规格请参见教程:云计算教程 | 用FLARE FEP计算相对结合自由能。
软件的安装在cloudam上的管理节点进行,具体的安装方法见LigandScout-Remote [2]技术文档,简单的总结如下:
- 安装Ligandscout
- 安装iserver
- 配置
- 执行iserver服务
1 2 | cd ~ tar -zxvf LigandScout_4_4_4_linux64_20200515.tar.gz |
1 2 3 | cd ~ wget https://www.inteligand.com/download/iserver/iserver_1.2.0_linux64.tar.gz tar -zxvf iserver_1.2.0_linux64.tar.gz |
解压后生成一个新的目录:ligandscout_server。
用编辑器打开ligandscout_server/application.properties,根据资源与LiandScout的安装实际情况编辑该文件完成配置。
用screen或nohup+&的方式,在后台启用iserver服务:
1 2 | screen ./iserver |
2. 本地Ligandscout的配置
本地绑定License机器的Ligandscout也需要做设置, 首先打开偏好设置:Ligandscout: Edit | Preferences | Program & Network |LigandScout Server。
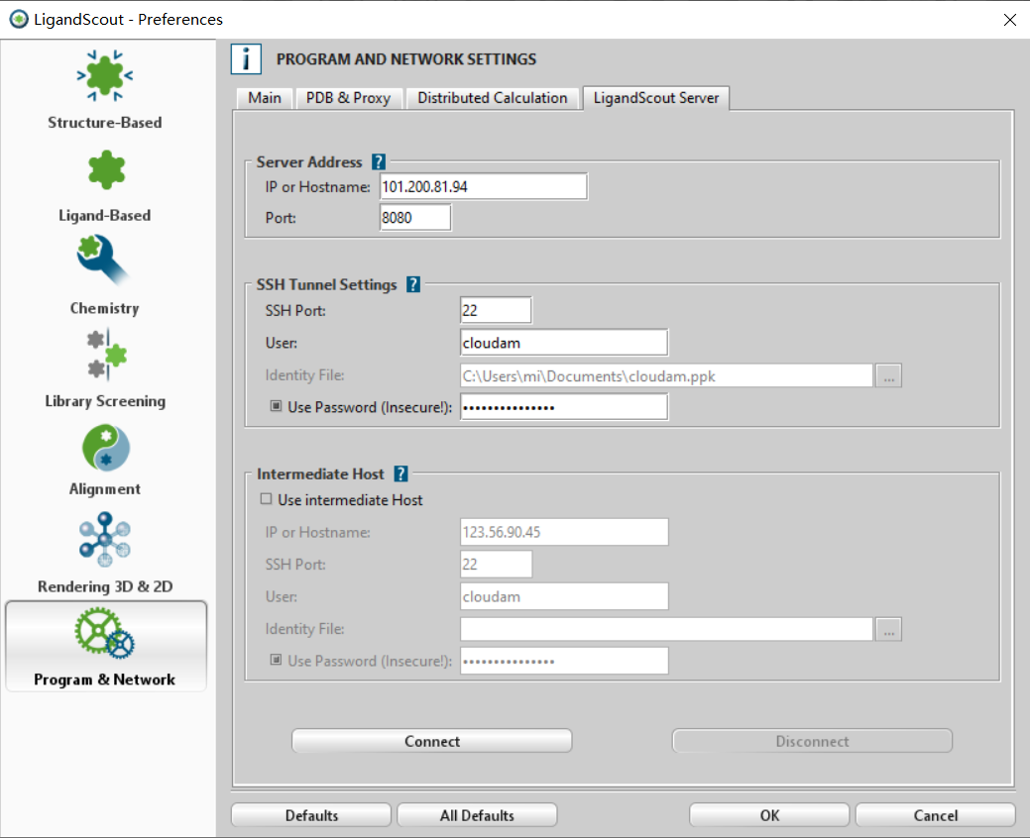
Figure 2. 本地LigandScout的配置
如图2所示,在Server Address部分需要填入启用iserver的管理节点的IP地址与端口。在SSH Tunnel Setting部分需要输入管理节点的用户名与密码,或者采用无密码登录的密钥文件。如果涉及到跳板机,需要在Intermediate host设置你在跳板机上的IP地址,用户名与密码。
现在,可以点击connect链接到服务器,如果一切顺利,会出现connection established对话框,点击OK即可(Figure 3)。
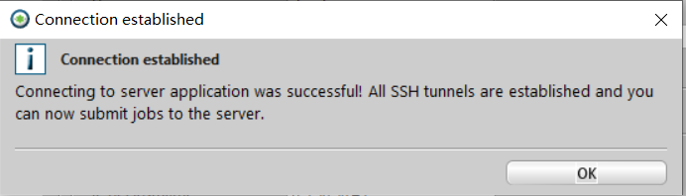
Figure 3. 连接服务器
与服务器连接的ligandscout在菜单栏右上角的“服务器连接”图标会高亮(绿色)显示,否则是灰色的(见Figure 4)。

Figure 4. 连接了服务器的Ligandscout图标为绿色高亮
2. 用Ligandscout-remote加载数据库
点击Ligandscout: File | Ligandscout_remote | Load Remote Database,打开加载远程数据库图形界面(Figure 5)。
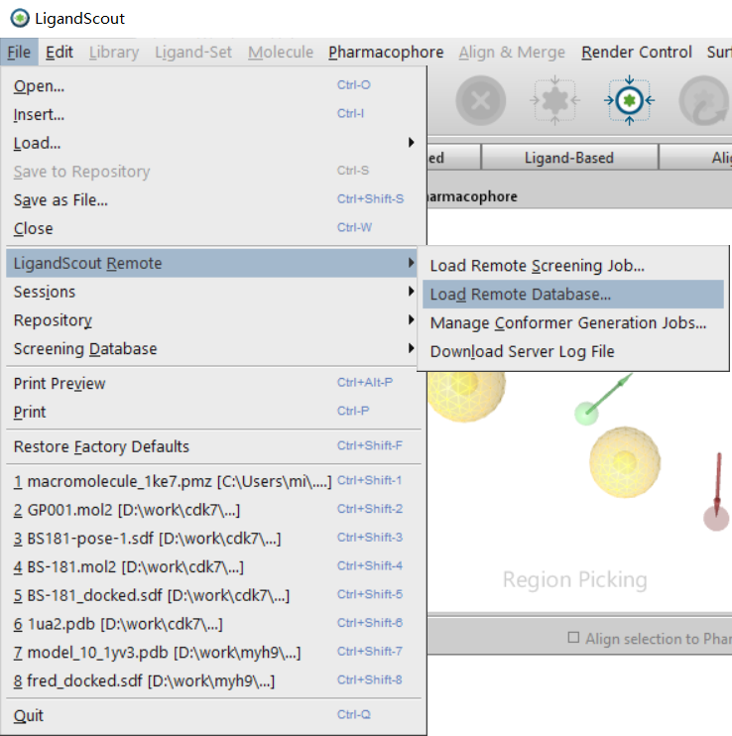
Figure 5. Ligandscout_remote Load Remote database
此时会弹出数据库加载对话框(Figure 6),选择需要的数据库,点击load按钮。
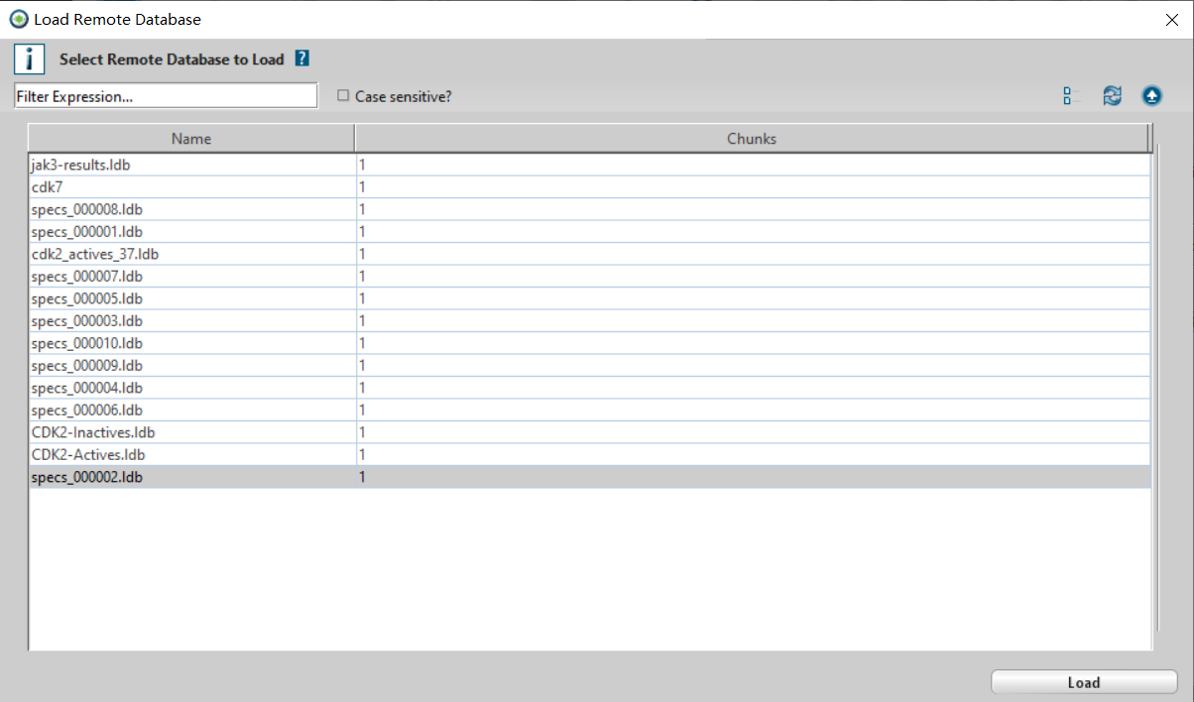
Figure 6. 数据库选择
成功加载的远程数据库会出现在screenning databases列表上,并有[R]开头,如图7所示。
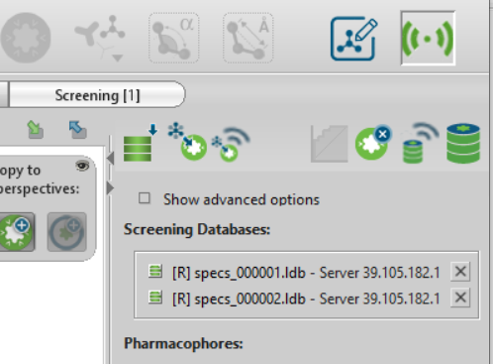
Figure 7. 成功加载的数据库
3. 远程数据库的虚拟筛选
点击图7的Perform remote screening图标,开始准备虚拟筛选,此时会弹出设置对话框,如图8所示。
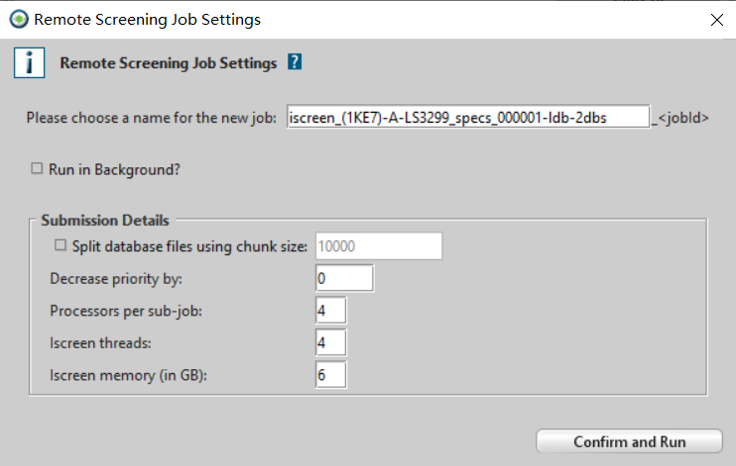
Figure 8. 远程虚拟筛选对话框
这里有几个与计算节点相关的设置:
- Processor per subjob
- Lscreening threads
- Lscreen Memory(in GB)
- split database files using chunk size
Ligandscout为每个子任务分配一个计算节点,这里要设定每个节点的核心数。在本次演示中,我采用的计算节点的核心数为4,因此设为4。
这个值一般设定为Processor per subjob或稍大(比如6)以提高计算效率。
在云端建立计算节点时,我给每个核心配置了2GB的内存,每个节点4个核心,所以每个节点配置了4×2=8GB的内存。但是,不能把所有的内存都给Ligandscout计算用,还需要留一点内存给操作系统。建议给ligandscout分配的内存为系统内存的75%,本演示用了6GB内存。
为了加速计算,可以将数据库分成几个子库分别同时进行虚拟筛选以加速计算。该值的意思是:拆分后每个子库含有的化合物数。在本演示中,我们将该值设为1000: 即每个子库为1000个化合物。
设定完毕,点击Confirm and Run按钮开始虚拟筛选。
4. 进度状态监控与结果加载
Ligandscout remote提供了工具进行进度状态监控以及结果加载。点击:LigandScout: File | Ligandscout remote | Load Remote Screening Jobs,如下图9所示。

Figure 9. 加载远程计算作业,监控虚拟筛选的进度状态
我们发现Ligandscout产生了24个子任务,分别在24个节点上进行计算。全部计算完毕大约1.5分钟完成。
计算完毕,点击图9右下角的Load按钮(未显示出来)可以将计算结果加载到本地的图形界面,如图10所示。

Figure 10. 加载远程计算结果后的图形界面
视频
链接:https://pan.baidu.com/s/1bg1vk9d0H-zyA-jbnlSg4w,提取码:9xer
文献
- Kainrad, T.; Hunold, S.; Seidel, T.; Langer, T. LigandScout Remote: A New User-Friendly Interface for HPC and Cloud Resources. J. Chem. Inf. Model. 2019, 59 (1), 31–37. https://doi.org/10.1021/acs.jcim.8b00716.
- Ligandscout-remote. Installation on Physical Clusters. https://docs.inteligand.com/ls-remote/installation-on-physical-clusters


