
摘要:Forge最新版V10.6发布,引入了新的QSAR技术并改进了诸多性能,包括:1)基于机器学习的建模方法;2)小数据集的定性SAR分析;3)对大项目响应更快的图形界面;4)改进了Blaze虚拟筛选的接口等等。
Forge V10.6正式发布
首先祝大家新春快乐!非常高兴地告知您,最新版的Forge V10.6正式发布了。Forge是一款为理解构效关系(structure-activity relationship, SAR)与化合物设计而开发的强大软件。本次升级聚焦于定量构效关系建模的新技术与方法的改进,以获得更强大预测能力的QSAR模型。
选择下一步要合成的分子
负责项目的化学科研人员通常知道什么样的分子具有相当大的概率具有活性。因为值得关注的化合物太多,所以需要一种方法帮他们对化合进行过滤和优先性排序。用预测性QSAR模型干这种事是一种好主意:您可以将分子送入模型,并立即获得关于该化合物是好还是坏的反馈。
然而,获得一个强大的预测性QSAR模型并不总是那么直截了当,对于许多科研人员来说这仍然是一个痛点:您不仅需要合理大小、活性(比如pKi,pIC50)跨度足够大的的训练集,而且还得有良好的描述符和建模算法。虽然我们无法在拥有具有合理大小和活性跨度的训练集上帮助到你,但我们可以帮助你完成其余的工作。
新版的Forge中引入了新的机器学习(ML)方法,包括支持向量机(Support Vector Machines, SVM)、关联向量机(Relevance Vector Machines, RVM)和随机森林(Random Forests, RF)。在新版Forge的Build Model选项框里不仅有之前的Field QSAR和kNN回归(k-Nearest Neighbors regression),还增加了SVM、RVM与RF等机器学习方法(Figure 1)。有了这些众所周知、健壮的统计工具,您可以更好地在项目工作中构建预测性模型。
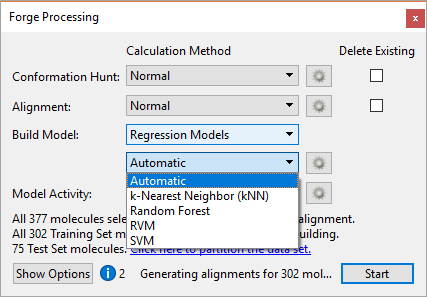
Figure 1. 新的机器学习方法显著地扩展了Forge V10.6中QSAR模型构建选项的范围
关于描述符(descriptor)
3D的静电(基于Cresset XED力场)与形状这两个描述符跟分子之间的识别直接相关,因此非常适用于化合物的活性与选择性的建模。Forge的Field QSAR以及新引入的机器学习方法正是使用这两种描述符进行建模;而kNN除了可以使用3D静电/形状描述符外,还可以使用2D指纹做为描述符。
算例
之前在Activity Atlas的算例里我们用到了从美国专利文献[1]提取的Orexin 2受体的配体数据集,并展示了Activity Atlas这种定性SAR研究方法的强大与便利性,全部的SAR信息浓缩、总结于一张3D等值图里。这次,我们还是用同样的数据集来展示Forge 10.6机器学习的性能。
377个Orexin 2配体被分成两个子集:(1)用来构建QSAR模型的302个化合物的训练集;(2)仅用于评估模型预测能力的75个分子的测试集。Figure 2显示了使用Field QSAR和ML方法生成OX2R pKi预测模型的结果。Filed QSAR,kNN和RF模型使用默认条件构建;对于SVM和RVM,Forge会自动进行调参并用于建模。
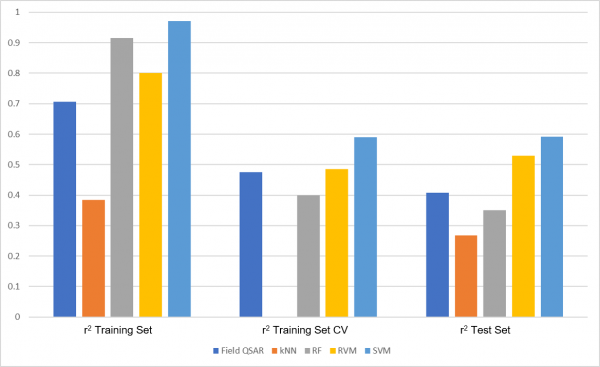
Figure 2. Field QSAR和ML方法在Orexin 2数据集上的性能表现: 训练集:用于构建模型的302个分子; 测试集:另外75个分子,仅用于评估模型的预测能力。
‘r2 Training Set’用于检查每个模型拟合训练集中数据的能力。它的取值范围从1(完美契合)到0(根本不适合)。从Figure 1中可以看到所有模型(除了kNN)都给出了极好的拟合结果。然而,这并不令人惊讶,因为ML方法因其适合于任何类型数据的能力而众所周知。
对模型质量进行更真实的检查来自于’r2 Training Set CV’。在交叉验证(CV)中,训练集中的一部分化合物暂时从模型中排除,剩余的化合物用于构建模型,然后用于预测排除的化合物的活性。毫不奇怪,’r2 Training Set CV’总是低于’r2 Training Set’,但是Field QSAR、RF、RVM尤其是SVM的结果仍然很好(kNN不计算此统计学指标)。
最后,更加逼近实际项目工作的是’r2 Test Set‘,因为该模型用来预测它以前从未见过的化合物的活性。大多数方法都给出了相当好的结果。SVM明显优于其他方法,其中r2测试集超过了0.59。
在一个真实的项目中,我会毫不犹豫地选择SVM来对我感兴趣、即将去合成的化合物列表进行过滤和优先排序,并确信这是对该数据集我可以获得的最佳预测能力。
kNN怎么样? 它在这个数据集上效果不佳; 这是不是意味着它不是一个好方法? 并不是的。 kNN是一种健壮的、众所周知的方法。当面与多个系列的化合物或者与来源于不同的生物学数据一起使用时特别有用。虽然在本算例中表现不佳,但并不能掩盖它在其他项目中表现良好的这一事实。
多种QSAR模型构建方法的重点是:您可以选择在特定项目中性能表现最佳的方法/模型。如果你认为分别计算所有这些模型一定很无聊,那么我有一个好消息:你真的不会无聊。 Forge会默认自动运行所有ML模型并为您选择最佳模型(图3)。

Figure 3. Forge自动构建所有可用的机器学习方法,并给出最佳模型。
理解SAR、选择待合成化合物
在一个项目中,化学科研人员工作的一个重要工作是设计下一代活性分子。要实现这一目标,您需要了解什么特征使得化合物具有活性,而又有什么特征破坏了化合物的活性。换句话说,您需要解释性模型。
不幸的是,机器学习算法在这方面不会帮助你:它们是复杂的方程,不能轻易地转换回3D配体-蛋白质相互作用的信息。幸运的是,Forge还为您提供了两个的工具:Field QSAR 3D与Activity Atlas中。Field QSAR建立的模型可以为您提供两全其美的预测和解释能力。Activity Atlas是一种定性模型(不能预测),它用活动悬崖来分析你的数据以了解SAR。
Forge V10.6中的Acitivity Atlas使用了一个新的活性悬崖算法,该算法可生成更详细的SAR地图,减少对单个化合物的依赖,尤其适用于中小型数据集。Figure 4同时给出了Orexin 2数据集的Field QSAR与活性悬崖等值图,你可以很方便的进行比较。
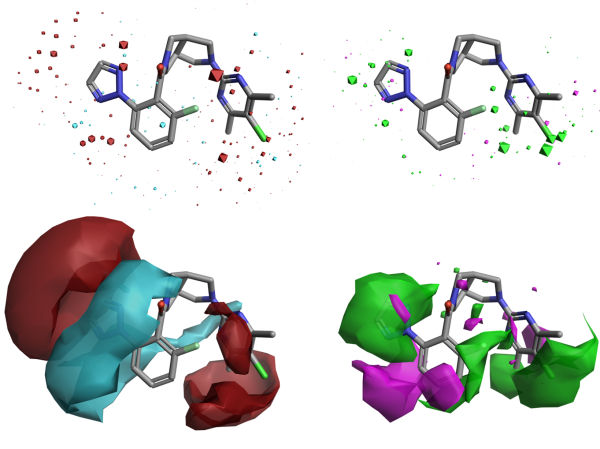
Figure 4. 上图:Field QSAR静电场(左)和立体场(右)系数。 下图:活动悬崖静电场概要(左)和活动悬崖形状场概要(右)。 颜色编码:红色=增加正静电势有利活性; 蓝色=更多负静电势有利于活性; 绿色=有利的立体体积; 洋红色=不利的立体冲突。
两种类型的等值图清楚且一致地表明更多正(红色)或负(蓝色)静电有利于化合物活性的地方,以及空间体积有利(绿色)或不利(品红色)的地方,为配体设计提供了宝贵的指示。
我没有高质量数据,但是我还想建模
有时,您拥有的数据并不像您希望的那样干净,不能用于QSAR建模的目的。 您可能有百分抑制率数据而不是pIC50或pKi; 数据来源于不同的测试实验; 或者仅仅是定性的数据。
Forge中的机器学习方法可以用分级数据建立用于将化合物排序、分类为一种类别(比如活性/非活性,活性低/中/高)的分类模型。 Forge还将提供可视化工具(例如混淆矩阵,Figure 5)和分类性能指标(比如精确度,召回率,知情度)以评估模型的性能并确定它是否足以用于项目工作。

Figure 5. Orexin 2分类模型的混淆矩阵与其它统计学指标
改进的图形用户界面
在Forge V10.6中,您将体验到强大的性能、出色的图片以及故事场景的平滑过渡,这要归功于新的图形引擎,它可以生成增强的3D对象(Figure 6)。
故事场景(storyboard scenes)是Cresset Flare最早的一个强大功能,你可以随时在使用软件的时候抓图,保存在Storyboard里。点击Storyboard里的任何一张图片就可以让软件返回到你抓取图片时软件所处的状态,就像一个时光穿梭机, 可以让你非常方便的回顾整个项目。

Figure 6. 新的图形引擎生成出色的图片
新版本还包括许多其它的图形用户界面性能提升,包括:
- 改进的QSAR模型小部件,以便在同一个界面里获取回归和分类模型的相关信息和图表,PCA组成份绘图,注释和“弹出”按钮,可以直观地比较不同的模型(Figure 7)。
- 改进的界面适于处理分级数据,以支持分类模型。
- 改进了Blaze结果窗口,可以显示每个Blaze模型的富集因子和统计学指标。
- 新功能:根据Murcko骨架自动为所选的分子分配角色。
- 新功能:根据指定的相似性度量方法和阈值进行聚类分析。
- 新选项:支持使用所有可用本地的CPU,放宽了之前Forge版本的16-CPU限制。
- 新版的图形界面对大型项目的响应更快,提高了常见操作的性能,例如应用过滤器,计算和与自定义图的交互,导出数据等等。
- Activity Miner和Activity Atlas的大型相似性矩阵计算速度更快、更健壮、内存占用更少。
- 改进了分子的2D显示。
- 改进了Activity Miner的图形用户界面。
- 绘制所选分子的回归曲线。
- 改进了结构过滤器,包含几种预定义过滤器:环,芳环,非环原子,手性原子,氢键供体和氢键受体。
- 改进了过滤器窗口,现在包括绿色/红色切换,以控制是启用还是禁用每个过滤器。
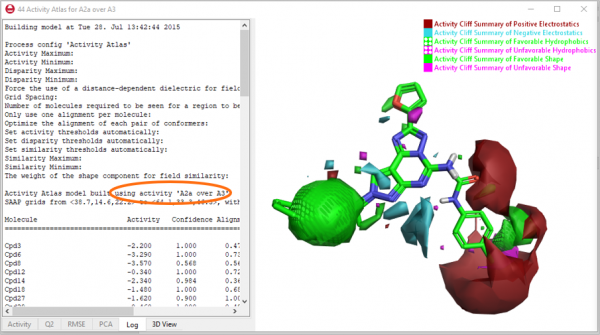
Figure 7. 用QSAR Model小部件中的“弹出”按钮比较不同的QSAR模型
文献
- US patent number 8,653,263B2
相关主题
- Forge v10.6抢先看
- 全部的Forge主题与教程:http://blog.molcalx.com.cn/tag/forge
- 深度学习建立沸点预测模型
试用与采购
任何需要,请联系我们


