
摘要:本文介绍了如何应用基于结构、基于配体的虚拟筛选方法发现新的化学类型。
原文:Lang, S. and Slater, M.J. (2024) “Virtual Screening Strategies for Identifying Novel Chemotypes,” Journal of Medicinal Chemistry. American Chemical Society. Available at: https://doi.org/10.1021/acs.jmedchem.4c00906.
编译:肖高铿/2024-05-23
活性化合物或系列化合物的识别是所有药物发现项目至关重要的第一步。理想情况下,这些化合物应该显示或具有在优化后显示良好物理化学和类药性质的潜力。物理筛选和虚拟筛选是一个过程,涉及用大量化合物去查询感兴趣的蛋白质靶标,以确定药物发现的可靠起点。定义筛选策略时需要考虑的一个关键因素是对特定蛋白靶标的了解。虚拟筛选需要对蛋白靶标和/或与靶标结合的配体有很高的了解。高通量筛选(HTS)不需要这种水平的知识,但需要获得大量的蛋白。
从广义上讲,虚拟筛选可分为两大类:基于结构的虚拟筛选和基于配体的虚拟筛选,每种筛选需要不同的信息。基于结构的虚拟筛选涉及将大量分子对接到蛋白中。这需要对蛋白的结构有深入的了解。例如,识别蛋白中的关键残基以及这些残基对配体结合的相关贡献。水分子在结合位点中的作用以及构象稳定性对这种类型的虚拟筛选也至关重要。药理学相关的3D蛋白结构对于基于结构的虚拟筛选至关重要。
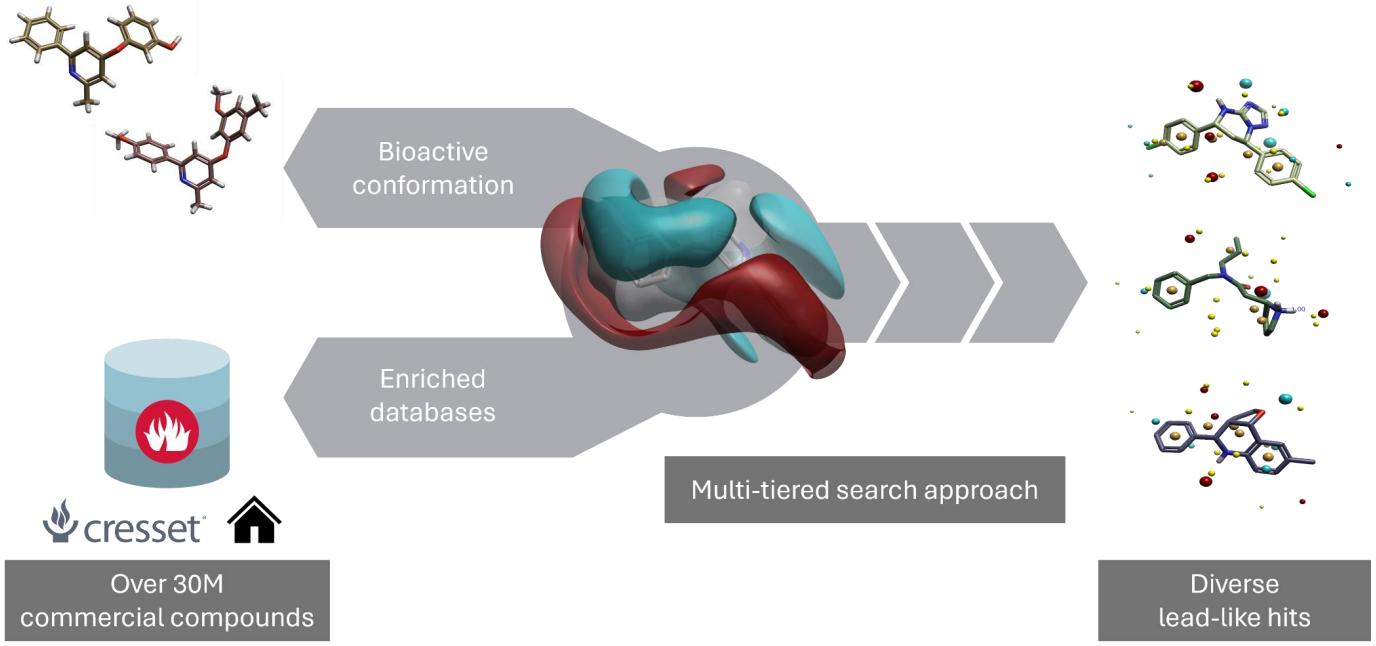
相反,基于配体的虚拟筛选不需要蛋白结构,甚至不需要特定蛋白靶标的知识,尽管这些信息在可用的情况下仍然有用。成功的基于配体的虚拟筛选需要的是以正确的生物活性构象构建的模板配体。例如,在以配体为中心的解决方案Blaze中,一种方式是构建一个模板,通过将配体周围的静电环境建模为场点来用于筛选。这不一定会与全局最小构象相同,因此需要准备工作来破译生物活性构象。在蛋白结构可获取的情况下,可作为排除体积用于筛选,以消除筛选中识别的化合物与蛋白表面发生碰撞的风险。
虽然虚拟筛选主要用于识别小分子起点,但模板配体不一定是小分子。小肽底物、天然蛋白质结合伴侣(例如在蛋白-蛋白相互作用中)和晶体堆积中的接触点都为基于配体虚拟筛选的模板设计提供了机会。
虚拟筛选增加了发现活性分子的可能性。它不能保证打分高的分子对感兴趣的蛋白靶标具有活性。通常,预计在虚拟筛选中识别出的分子中,平均有1%以上将在针对靶标的实验中得到验证。虽然这看起来可能并不高,但与无偏倚的高通量筛选预期的0.01-0.1%命中率相比,使用虚拟筛选对筛选库的富集使评估的分子具有活性的概率提高了10-100倍。这意味着对从虚拟筛选结果中选择500-1000个分子进行实验筛选,相当于对5万-10万个分子进行了高通量筛选。由于从虚拟筛选中获得的分子多样性是成功的关键,因此筛选后的分级审查非常重要。根据logP/D、TPSA、HBD/HBA等参数,去除没有显示出可接受理化性质的化合物是至关重要的。虚拟筛选打分的度量标准之一是与配体模板的3D形状相似性,以及对接打分和静电互补性(EC)打分,后两者需要用到靶标蛋白结构。由于这些度量标准对分子的打分方式不同,因此在选择化合物时必须单独考虑每个指标。一个化合物可以通过不同的方法获得更好的打分,但是在现阶段,尚不清楚那种指标更可能与活性相关。最后,根据《药物化学杂志》作者投稿指南,虚拟筛选的结果列表应经过筛选以去除PAINS与反应性基团。
聚类是确保分级审查后数据具有化学结构多样性的关键步骤。通过根据化合物的结构对其进行分组,可以确保最终结果不以特定骨架类型为主,这些骨架使用优先级度量标准打分很高,但这些打分可能无法转化为可测量的活性。在实验验证之前对结果聚类的另一个优点是,可以挖掘出各类化合物的构效关系(SAR),因为在已知一个类别的化合物中包含有苗头化合物后,可以随后筛选来自该活性类别里尚未经过测试的化合物。
用于虚拟筛选的化合物库需要预先准备。为了确保化合物可用于实验验证,这需要将虚拟筛选库限制于商业可供购买的化合物,总共大约有2300万的化合物可供常规筛选。然而,对于拥有内部高通量筛选库的机构,可能包含有专有的化合物,这些化合物库也可以用于虚拟筛选,以便从中选择一个子集针对靶标进行虚拟筛选。在难以制备足够的蛋白用于完整高通量筛选的情况下,或为了识别可能被初步高通量筛选遗漏分子的情况下,这么作特别有利。
最近,由于Enamine Real等化合物库的发展,其中包含了从容易获得的砌块合成易得的虚拟化合物,因此,可用于虚拟筛选的现货化合物不再是限制因素。然而,将筛选数据库从2300万个化合物增加到60亿个化合物,提出了一个完全不同的挑战——虚拟筛选的规模。因此,可以应用基于合成子的方法,其中一个例子在Ignite中得到验证,这涉及对用于创建完整数据库的每个砌块对靶标蛋白进行筛选,然后仅用打分足够高的合成子来生成最终的分子。接着对生成的分子进行一个完整的筛选,就像前面描述的过程那样生成一个虚拟筛选列表,随后对其进行分级审查,推荐出500-1000个化合物用于测试。
虚拟筛选可以针对特定靶标筛选以识别新化学类型的化合物而无需前期大量投资来管理、存储高通量化合物库。虽然它仍然需要对大量化合物进行测试,但它不需要使用处理高通量筛选所需的自动化液体处理/移液系统。这使得虚拟筛选对各种规模的药物发现机构来说不仅具备可及性而且具有吸引力。在筛选之前产生的前期知识信息,再加上筛选后的分级审查,如果得以有效执行,也可以提高项目早期从苗头到先导(Hit-to-Lead)阶段的效率。


