
摘要:药物发现各个阶段的高损耗率推动了人们探索更大化学空间的需求,基于结构虚拟筛选因此而势头正盛。本文从贝叶斯的角度讨论了其作为可持续苗头化合物发现可行策略的缺点,以及已有库筛选的命中率与计算方法的性能。分享了从八个成功筛选中学习到的选择虚拟苗头化合物进行实验验证的经验教训,其中一个筛选为目前正在临床试验中的候选药物的发现作出贡献。
原文:Hongtao Zhao. The Science and Art of Structure-Based Virtual Screening. ACS Medicinal Chemistry Letters. 2024. https://doi.org/10.1021/acsmedchemlett.4c00093.
编译:肖高铿/2024-03-27
自20世纪90年代以来,高通量筛选(HTS)一直是药物发现中用来识别调节所选靶标生物活性的化合物主要策略1。筛选大量化合物库既费力又昂贵。筛选库通常是专有的,生物技术公司和学术实验室无法访问。DNA编码库(DEL)技术2,3和基于片段的先导化合物发现(FBLD)4,5是HTS的补充。基于结构的虚拟筛选(structure-based virtual screening)旨在通过预测库化合物与所选靶标的亲和力,根据其预测的结合模式而不需要先验的活性知识,仅选择少数化合物进行实验测试。多年来,在药物发现领域,虚拟筛选的应用呈指数级增长6-8。药物发现各个阶段的高损耗率持续推动了对更大化学空间探索的需求。基于反应的库枚举和最近的人工智能生成模型产生的巨大虚拟化学空间再次使虚拟筛选成为人们关注的焦点9-13。
高通量筛选仍然是发现新药的主要工具;这使得虚拟筛选类似于彩票,是一种快速廉价的选择,可以试试运气。鉴于有大量虚拟筛选的报道,发现新的苗头化合物并不奇怪,有些甚至已经被优化为临床候选药物14。考虑到偶然性在药物发现中的地位,我关注的是虚拟筛选是否可以作为一种可持续且可靠的苗头化合物发现方法,如果是这样,哪些步骤限制了它的成功?
表1. 从6个虚拟筛选中选择的苗头化合物
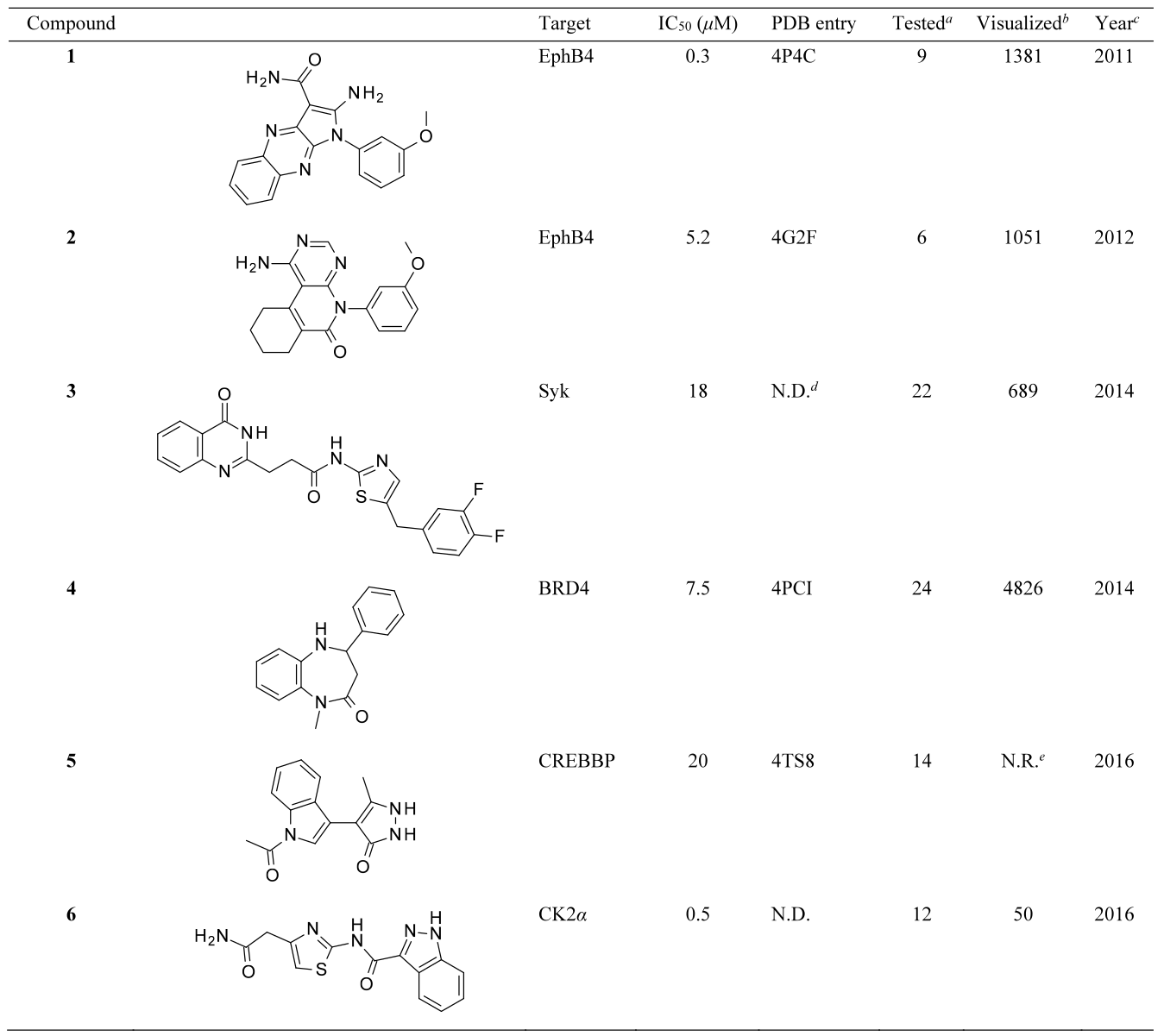
进行了六次基于结构的虚拟筛选,涉及EphB415,16、 EphA317、Zap7018、Syk19以及CK2α20等激酶靶标,此外还包括两次针对BRD421和CREBBP22的溴域靶标。通过对约20个化合物的实验测试表明,命中率范围为9.1%~75%,中位数为44.4%。IC50值在20~0.3μM之间,因此苗头化合物的活性与HTS相当。使用SciFinder检查了骨架新颖性。表1列出了六个代表性苗头化合物。在对BRD4和CREBBP进行的两次虚拟筛选时,溴域是新兴的治疗靶点,报道的配体很少,这是在2010年JQ1发表的里程碑之后P23。值得注意的是,预测的4个苗头化合物的结合模式都得到了晶体学的证实16,21,22,24,这有力地支持了其发现与应用的计算方法之间的因果关系。对激酶苗头化合物1和2进行了两次化学优化16,24,对CREBBP苗头化合物5进行了一次化学优化5。注意到,对1的优化发现一系列活性在个位数nM级别的DFG-in/out激酶抑制剂24。对化合物7进行一系列基于细胞的测试、基因表达谱和PK/PD研究的临床前研究25。令人鼓舞的是,据报道,化合物7是发现药物候选物RP-6306的起点,该药物目前正在进行各种实体瘤的临床试验26。在其开发之后,Insilico Medicine最近报告发现了一种新的MYT1抑制剂,表现出对WEE1具有选择性27。综上所述,可以说基于结构的虚拟筛选确实是一种可持续的方法,赋予了新的化学类型,对药物发现具有明显的影响。
尽管取得了多次成功,但由于视觉检查的主观性,与实验室同行的沟通一直具有挑战性,视觉检查由知识、经验和一点巫术组成。视觉检查是从数百到数千个预测为活性的化合物中挑选出约20个化合物的过程(表1)。批评不是针对选择过程本身的黑箱特点,因为如有必要,可以清楚地说明具体流程,而是针对其他人在虚拟筛选任务中取得这种成功的科学依据和可重复性。
那么,为什么需要目视检查呢?让我们从理解化合物在预测为活性p(P|PP)时成为真正苗头化合物的可能性开始。条件概率或阳性预测值可以通过贝叶斯定理估算:
$$p(P|PP)={p(P)p(PP|P) \over {p(P)p(PP|P)+p(N)p(PP|N)}} \cdots (1)$$
其中p(P)和p(N)分别是筛选库的阳性率和阴性率;p(PP|P)和p(PP|N)分别是所应用筛选方法的召回率和假阳性率。
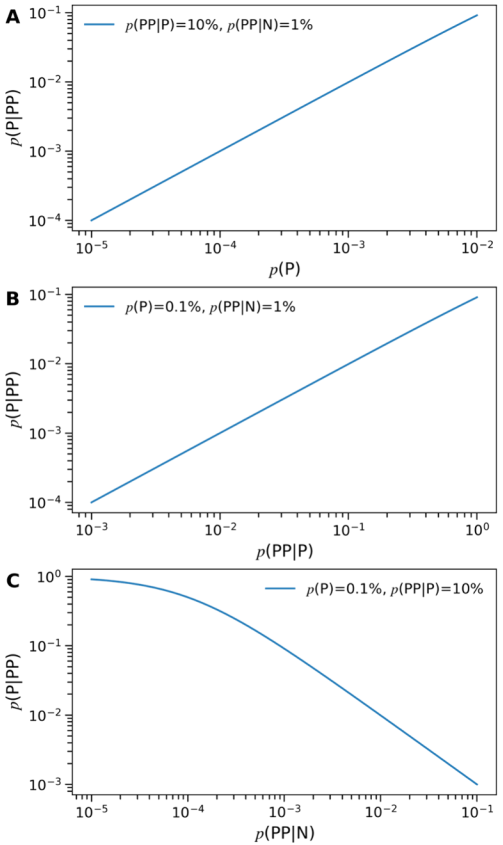
图1. 库筛选方法阳性预测值(p(P|PP))的模拟,(A)命中率,(B)召回率和(C)假阳性率
给定一个召回率为10%、假阳性率为1%的虚拟筛选方案,随着筛选库的命中率从0.001%增加到1%,阳性预测值(p(P|PP))从0.01%线性增加到10%(图1A)。据报道28,筛选经典的诺华HTS库的命中率为0.001%至0.151%。在辉瑞公司进行的10次HTS试验中29,确认的命中率在0.007%至0.143%之间,中位数为0.075%。请注意,用于虚拟筛选的商用库的命中率预计低于公司专有HTS库。对于命中率远低于0.1%的商用库,基于结构的虚拟筛选可能会将苗头化合物富集到几百或几千个化合物中。但是,从中随机选择50个虚拟苗头化合物进行测试不太可能得到任何活性化合物。对于超大型虚拟库对接筛选尤其如此30。这说明了视觉检查的必要性,尽管其具有主观性。
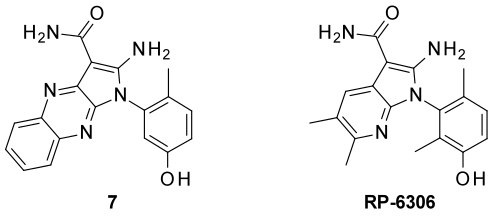
因此,筛选库的选择对虚拟筛选的成功起着至关重要的作用。最近人们已经对虚拟库的扩展建模进行了讨论30,本文不作赘述。相反,值得详细说明的是基于虚拟片段的虚拟筛选,它具有FBLD的优点。化合物5是从GSK2801的1-indolizin-3-ylethanone片段骨架跃迁到1-indol-1-ylethanone,随后对约200个有现货库存衍生物的虚拟筛选而识别到的。由于这两个片段从视觉上看具有几乎相同的形状和药效团,因此这些衍生物预计比随机选择的集合具有更高优先级的命中率,最后的测试证明在14个化合物中有个7具有活性22。值得注意的是,化合物5与GSK2801的Tanimoto相似系数为0.28。同样,对生物活性化合物中频繁出现的虚拟片段库进行的筛选识别出了N-甲基-1H-吲唑-3-甲酰胺(N-methyl-1H-indazole-3-carboxamide)。然后对其商业化的衍生物进行第二次虚拟筛选,并从排名前50的化合物中选出12个化合物进行测试。其中包括化合物6在内的9个化合物具有活性20。基于锚的化合物库裁剪方法(anchor-based library tailoring approach,ALTA)首先从筛选虚拟片段开始,从化合物库中拆解出锚定片段,然后对全尺寸衍生物进行第二次虚拟筛选31。人们已经证明这个方法在前瞻性的虚拟筛选中是成功的16,21,31,32,并且已经将几个苗头化合物优化为有效的结合剂16,33-35。可以说,第二步中的筛选库具有很高的优先级命中率,因为它们是由锚定片段富集到的。
在已有命中率为0.1%且假阳性率为1%的情况下,随着召回率从0.1%增加到100%,阳性预测值从0.01%线性增加到10%(图1B)。值得注意的是,在召回率为100%时,由于假阳性率的原因,阳性预测值达到10%的极限。配体可以结合到不同位点,例如正构与变构位点。基于结构的虚拟筛选通常将库化合物对接到具有刚性蛋白质假设的预定义位点。基于物理学的,应用越精确的计算方法,发现结合在其它位点或需要蛋白诱导契合的苗头化合物的可能性就越小。对此,人们提出系综对接或诱导契合对接来应对蛋白质的可塑性问题;然而,这也可能增加假阳性率。同样地,随着假阳性率从10%降低到0.01%,阳性预测值线性增加,在假阳性率为0.001%时接近100%(图1C)。为了减少假阳性,人们常用诸如保守的氢键相互作用或亲脂口袋填充之类的药效团特征来优选预测的结合模式。这种方法诚然有效15,但有一个明显的缺点,即阻止了发现具有不同作用模式苗头化合物的可能性。
将结构相似的化合物聚类在一起有助于进行目视检查。每类挑选几个代表性化合物可以增加找到真正苗头化合物的机会,因为不同化学型的内在命中率不同,从而影响p(P|PP)。目视检查的一个重要方面是用知识来补充基于近似的计算方法,这有助于减轻因方法漏洞而产生的假阳性30。配体构象张力能或扭转角张力能对基于力场的打分方法提出了普遍挑战,因为在虚拟的无限化学空间中扭转角模式的范围非常广泛。例如,两个苗头化合物3和6预测的结合模式含有高能构象的2-酰胺基噻唑19,20,这是因为羰基氧和噻唑氮之间的孤对电子排斥而不稳定,并进一步受到超共轭硫-孤对电子相互作用的不利影响36。请注意,超共轭是一种量子效应,需要在力场中进行特殊处理,而开发高质量的力场是一项重大任务。用剑桥结构数据库进行分析可以帮助识别那些含有不切实际的高能扭转角结构37-39。 虽然扭转角过滤可以自动化40,但还应该注意,蛋白质的松弛可能会释放扭曲角张力,而蛋白在基于结构的虚拟筛选中通常是保持刚性的。扭转张力在多大程度上释放取决于每个从业者在目视检查中的意识和感知。其他考虑因素涉及特定的打分方法,如去溶剂化。最后,一个实际考虑因素是骨架的新颖性,这本质上是主观的,也与已知的苗头化合物有关。这通常会导致人们对虚拟筛选重要性的争论。
值得一提的是,大多数苗头化合物在可视化检查过的化合物中排名前半部分,甚至在前四分之一,其中一些最有活性的化合物在前100名中。虚拟筛选的目的是确定一个合适的起点,其可以很容易地发展成一系列适合于在先导化合物优化中进行研究的化合物。在选择虚拟苗头化合物进入实验验证时的可开发性评估可以加速随后的苗头化合物优化,就像苗头化合物1和2的进展一样16,24。例如,先导化合物7是在化学优化的第一周合成的第一个化合物24。仅合成了化合物2的一个衍生物,就显示出抑制活性增加了近50倍16。毋庸置疑,与高通量筛选苗头化合物的分级整理类似,对成千上万的化合物可视化检查是一项艰巨的任务。因此,通过虚拟筛选寻求高质量的苗头化合物及其科学价值应该得到同行评审和科学期刊的尊重与认可,而不应被视为一种低劣的方法。
总而言之,在虚拟筛选中,选择几十个虚拟苗头化合物进行测试是一种常见的做法,以这种方式进行基于结构的虚拟筛选的成功高度取决于从业者的知识和经验。对于利益相关人与计算化学家的期望而言,认识到这个局限性至关重要。通常,有必要对数百种尽可能结构多样的化合物进行测试;在挑选化合物时,不要选择那些在预测的结合模式中具有高扭转角能量的化合物,而应偏向选择那些有能力形成已知结合剂保守关键相互作用的化合物。


